Apache Kafka Raft (KRaft): Apache Kafka and how it's finally without Zookeeper.


The Basics, Apache Kafka
Let's start with some context.
Apache kafka is is an open-source event streaming platform that can transport huge volumes of data at very low latency.
Kafka lets you:
Publish and subscribe to streams of events
Store streams of events in the same order they happened
Process streams of events in real time
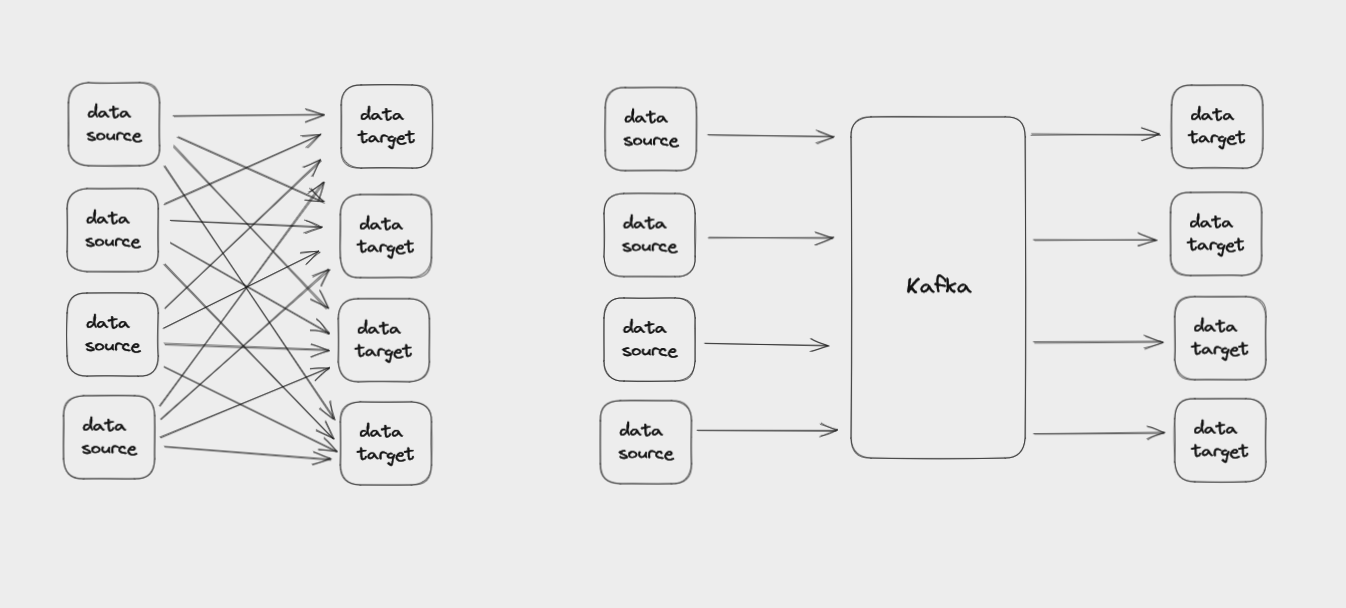
The main thing Kafka does is help you efficiently connect diverse data sources with the many different systems that might need to use that data.
Architecture of Kafka
So all in all , Kafka is a distributed streaming platform.
Streams are just infinite data, data that never ends. It just keeps arriving, and we can process it in real-time.
And Distributed means that Kafka works in a cluster, each node in the cluster is called Broker. Those brokers are just servers executing a copy of apache Kafka.
Messaging
Messaging, very briefly, it’s just the act to send a message from one place to another. It has three principal actors:
Producer: Who produces and send the messages to one or more queues;
Queue: A buffer data structure, that receives (from the producers) and delivers messages (to the consumers) in a FIFO (First-In First-Out) way. When a message is delivered, it’s removed from the queue.
Consumer: Who is subscribed to one or more queues and receives their messages when published.
What's Zookeeper?
Zookeeper acts as a centralized service and is used to maintain naming and configuration data and to provide flexible and robust synchronization within distributed systems. Zookeeper keeps track of status of the Kafka cluster nodes and it also keeps track of Kafka topics, partitions etc.
Zookeeper it self is allowing multiple clients to perform simultaneous reads and writes and acts as a shared configuration service within the system. The Zookeeper atomic broadcast (ZAB) protocol i s the brains of the whole system, making it possible for Zookeeper to act as an atomic broadcast system and issue orderly updates.
Why did we need zookeeper for Kafka?
Distributed Coordination: Kafka operates as a distributed system, with multiple brokers handling message storage and processing. Zookeeper provides distributed coordination among these brokers, ensuring that they can work together efficiently and reliably. It helps in leader election, maintaining broker metadata, and managing synchronization between brokers.
Cluster Management: Zookeeper keeps track of the Kafka cluster's overall health and membership. It maintains information about which brokers are currently available, their configuration, and the topics being managed by each broker. This information is critical for clients and brokers to discover and communicate with each other seamlessly.
Metadata Storage: Kafka relies on Zookeeper for storing crucial metadata, such as information about topic configurations, partition assignments, and consumer group offsets. This metadata is essential for ensuring fault tolerance, load balancing, and reliable message delivery within the Kafka cluster.
Fault Tolerance: Zookeeper itself is designed to be highly available and fault-tolerant. It uses a replicated consensus protocol (ZAB - Zookeeper Atomic Broadcast) to ensure that changes to its state are coordinated and consistent across multiple nodes. This resilience makes Zookeeper a dependable foundation for managing Kafka's distributed environment.
Difficulties of Zookeeper
Scalability: ZooKeeper is not designed to handle a large number of clients or requests. As Kafka clusters grow in size and traffic, ZooKeeper can become a bottleneck and affect the performance and availability of Kafka.
Complexity: ZooKeeper adds another layer of complexity and dependency to Kafka’s architecture. Kafka users and operators have to install, configure, monitor, and troubleshoot ZooKeeper separately from Kafka. Moreover, ZooKeeper has its own configuration parameters, failure scenarios, and security mechanisms that are different from Kafka’s.
Consistency: ZooKeeper guarantees strong consistency, which means that all the nodes in the cluster see the same view of the data at any given time. However, this also means that ZooKeeper requires a quorum (majority) of nodes to be available to process any request. If a quorum is not available, ZooKeeper cannot serve any request and becomes unavailable. This can affect Kafka’s availability as well, especially in scenarios such as network partitions or data center failures.
Complex and difficult to manage.
Introduces a bottleneck between the active Kafka controller and the ZooKeeper leader.
Meta-data changes (updates) and failovers are slow.
KRaft
KRaft stands for Kafka Raft Metadata mode, which means that Kafka uses the Raft consensus protocol to manage its own metadata instead of relying on ZooKeeper.
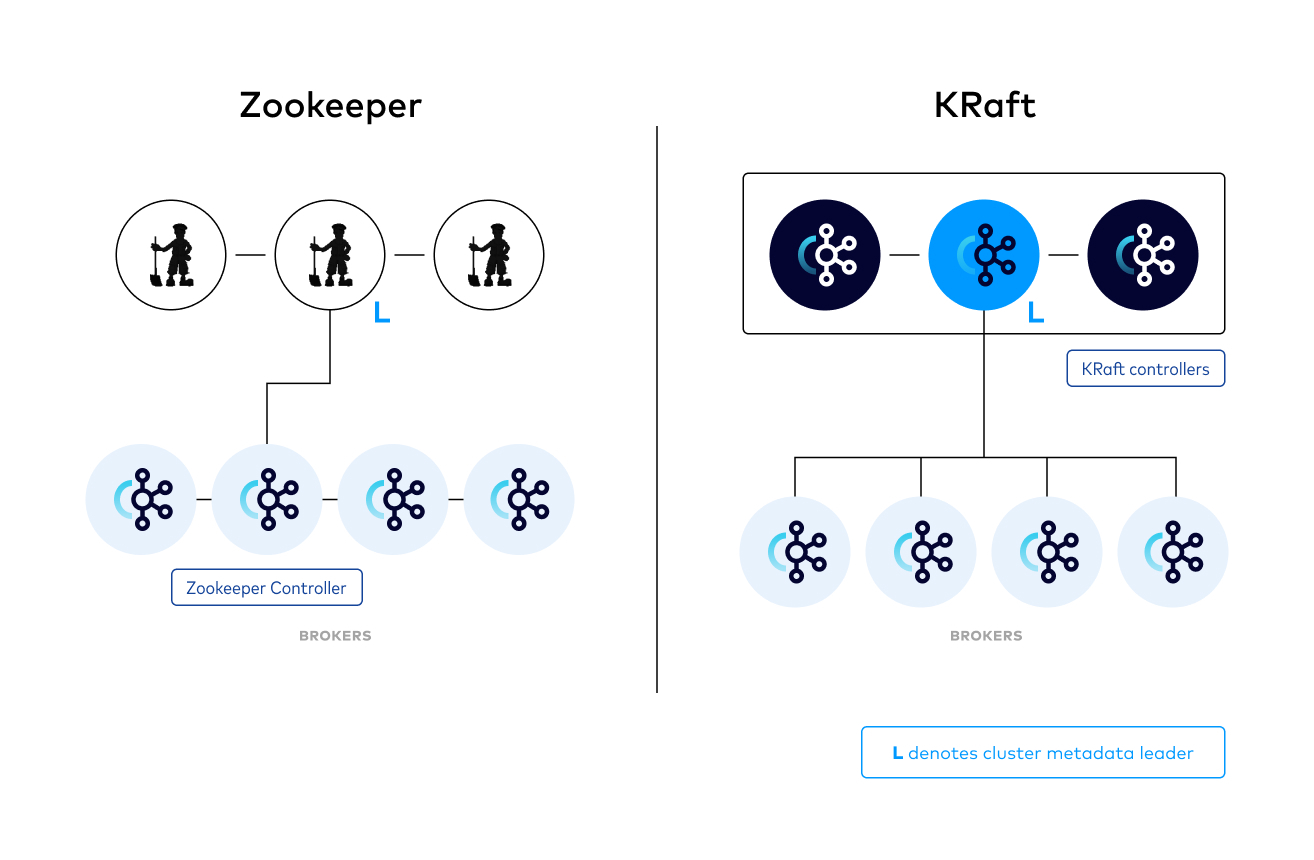
Apache Kafka Raft (KRaft) is the consensus protocol that was introduced in KIP-500 to remove Apache Kafka’s dependency on ZooKeeper for metadata management. This greatly simplifies Kafka’s architecture by consolidating responsibility for metadata into Kafka itself, rather than splitting it between two different systems. KRaft mode makes use of a new quorum controller service in Kafka which replaces the previous controller and makes use of an event-based variant of the Raft consensus protocol.
Benefits of Kafka’s new quorum controller
KRaft enables right-sized clusters, meaning clusters that are sized with the appropriate number of brokers and compute to satisfy a use case’s throughput and latency requirements, with the potential to scale up to millions of partitions
Improves stability, simplifies the software, and makes it easier to monitor, administer, and support Kafka
Allows Kafka to have a single security model for the whole system
Unified management model for configuration, networking setup, and communication protocols
Provides a lightweight, single-process way to get started with Kafka
Makes controller failover near-instantaneous
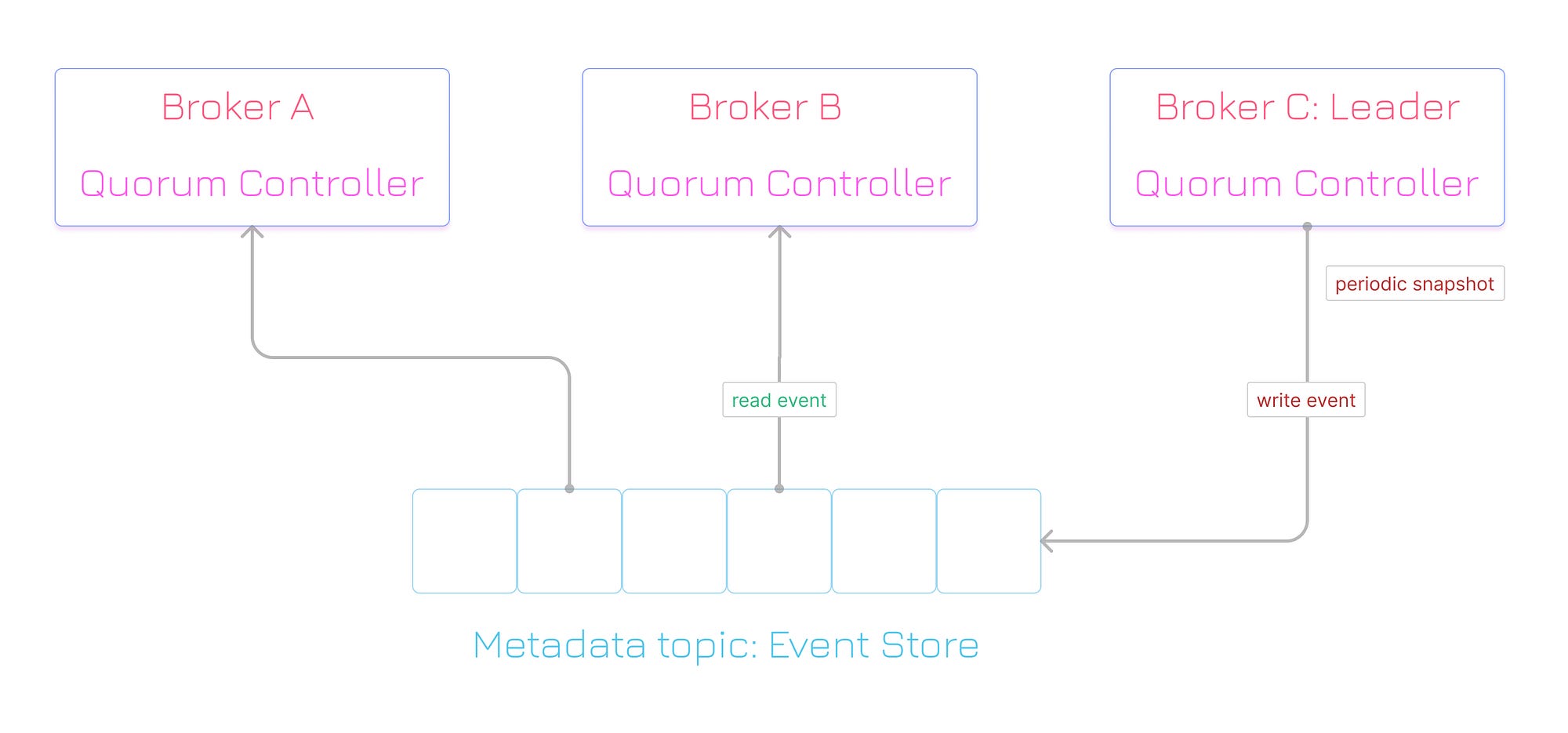
The quorum controllers use the new KRaft protocol to ensure that metadata is accurately replicated across the quorum. The quorum controller stores its state using an event-sourced storage model, which ensures that the internal state machines can always be accurately recreated. The event log used to store this state (also known as the metadata topic) is periodically abridged by snapshots to guarantee that the log cannot grow indefinitely.
The other controllers within the quorum follow the active controller by responding to the events that it creates and stores in its log. Thus, should one node pause due to a partitioning event, for example, it can quickly catch up on any events it missed by accessing the log when it rejoins. This significantly decreases the unavailability window, improving the worst-case recovery time of the system.
Let's Try it out!
If it wasn't obvious by now, the prerequisite is to have Apache Kafka Installed. Version 3.3 or after.
Here's where you can install the same:
https://kafka.apache.org/downloads
- Generate a Cluster UUID
$ KAFKA_CLUSTER_ID="$(bin/kafka-storage.sh random-uuid)"
- Format Log Directories
$ bin/kafka-storage.sh format -t $KAFKA_CLUSTER_ID -c config/kraft/server.properties
- Start the Kafka Server
$ bin/kafka-server-start.sh config/kraft/server.properties
Once the Kafka server has successfully launched, you will have a basic Kafka environment running and ready to use.
- Once it's done, go ahead and create a topic with the below command:
sh bin/kafka-topics.sh --bootstrap-server localhost:9092 --create --topic NewTopic --partitions 3 --replication-factor 1
This creates a topic with 3 partitions and replication factor of 1.
- Let's start our Producer with the following command:
sh bin/kafka-console-producer.sh --broker-list localhost:9092 --topic NewTopic
- Let's start our Consumer with the below command:
sh bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic NewTopic --from-beginning
And all set! We should able to send messages from our producer:

And be able to consume it from our consumer!
